Kaggle のTitanicチュートリアルやってみたメモ
はじめに
Kaggleはどうなんだろうとふと思い立ちTitanicチュートリアルをやってみました。Submitまでの大きな流れは理解できたと考えます。初見のため他の方のブログを参考にし、たまたま openml のデータセットを用いる例を参照したことで、submit時にそれなりに迷いましたが、無事submitまでたどりつきました。迷って試行錯誤したことでより理解できたと良い方向に考えています。
Submit 記録↓
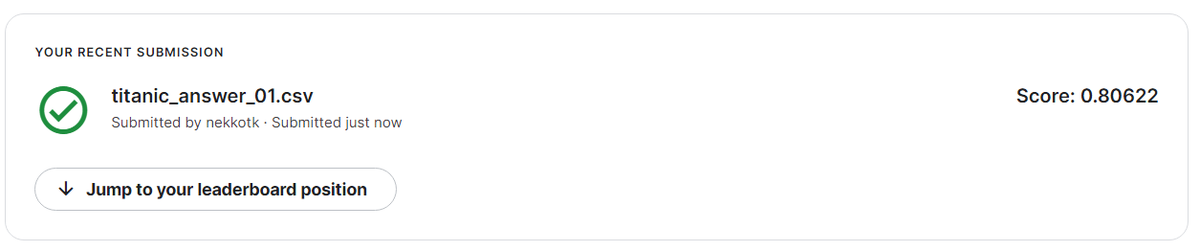
対象チュートリアル
実施環境
環境としてはGoogle Colab 環境で実施しました(Kaggle Jupyter Notebook、Google Colab どちらの環境がベターなのかわかりませんが、Google Colab は他でも使用していたため、今回も Google Colab を使用しました)。
Submit までの大きな流れ
- データセット取得
- データ前処理
- 学習、予測
- Submit
具体的な実施方法は多くのブログでも記載されている為、詳細はここでは記載しませんが素直に Kaggle が用意した学習データで学習し、テストデータを用いて予測、結果提出の流れがよさそうです。
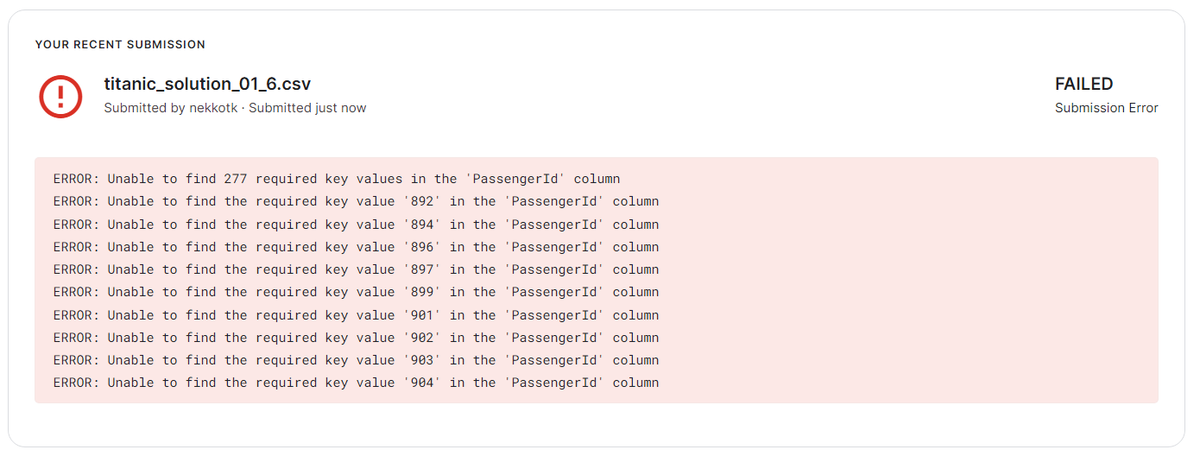
はまった点(openmlのdatasetを使ったためにはまった点)
- Kaggleのdataset と列名が異なる
- Kaggleで submitするには列名を合わせる必要があるが、何を submit 必要なのかすら知らない初見では迷う。学習モデルを適用する際にも形式を合わさないといけない点も面倒。
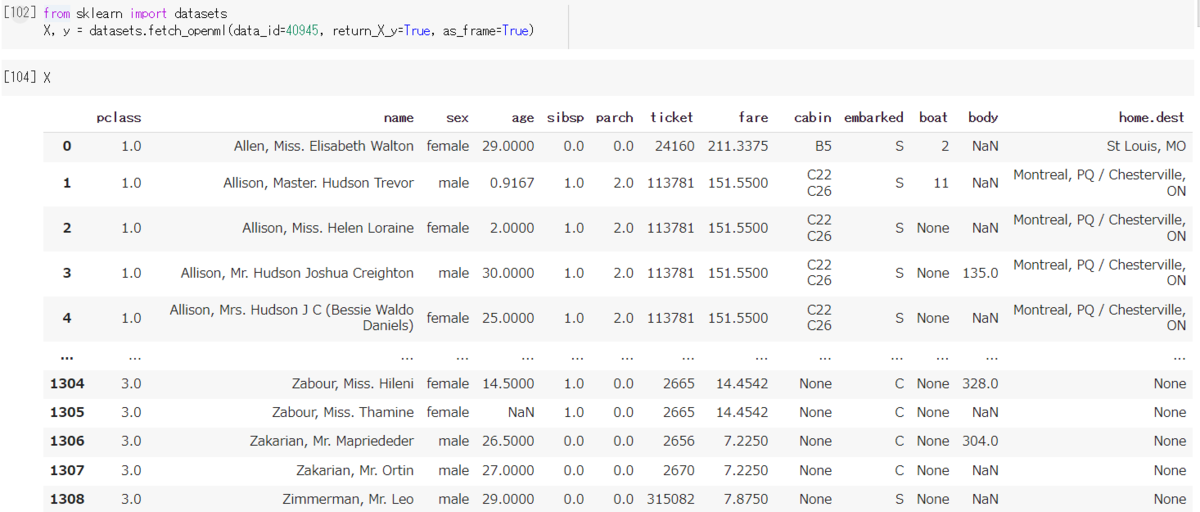
- openml の dataset はこちら
- Kaggle の dataset はこちら
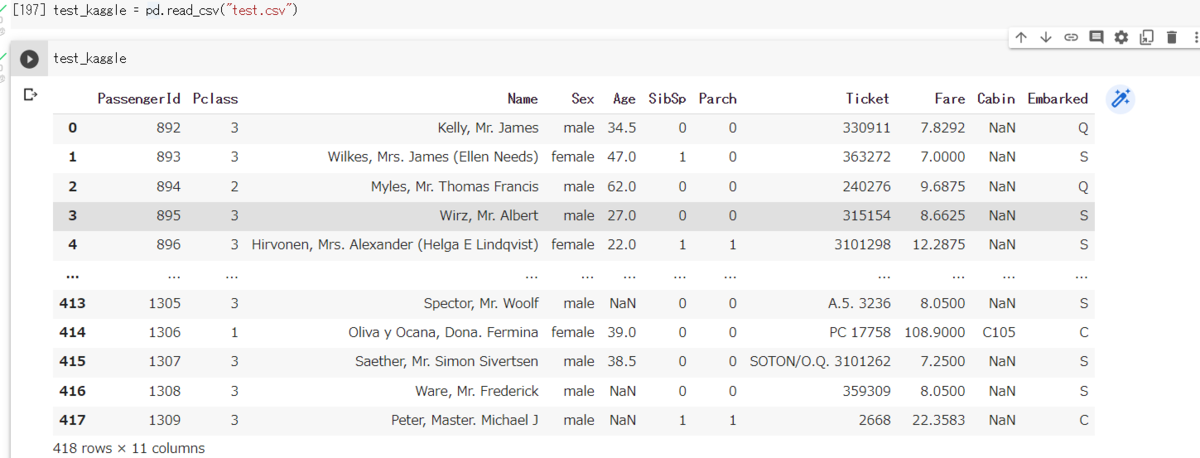
- test データと training データが分かれていない
実施したコマンド達(メモ)
- X.isnull().sum()
- データ欠損チェック用(欠損数 0以外のデータで重要そうなものは対処必要)

- データ欠損チェック用(欠損数 0以外のデータで重要そうなものは対処必要)
- X["age"] = X["age"].fillna(X["age"].median())
- 中央値で補う
- X["embarked"] = X["embarked"].fillna("S")
- 多い数で補う
- X["sex"] = pd.get_dummies(X["sex"], drop_first=True)
- 文字列データを数値に置き換え
- 文字列データを数値に置き換え
-
X = pd.concat([X, pd.get_dummies(X["embarked"], prefix="embarked")], axis=1).drop(columns=["embarked"])
- 複数値を持つカラムを個別のカラムに分離
-
PassengerId = test_y.index.astype(int)
- int 指定
- my_solution = pd.DataFrame(pred_X, PassengerId, columns = ["Survived"])
- PassengerId と pred_X を組み合わせる
- my_solution.to_csv("titanic_solution_01.csv", index_label = ["PassengerId"])
- csvファイル出力
- feature_columns =["Name", "SibSp", "Parch", "Ticket", "Fare", "Cabin", "Sex", "Age", "Embarked","Pclass"]
- test_kaggle = test_kaggle.drop(columns=feature_columns, axis=1)
- 対象カラムをdrop
- from sklearn.metrics import accuracy_score
- accuracy_score(test_y, pred_X)
- 予測がどの程度あってるか確認
- from sklearn.model_selection import train_test_split
- seed=0
- train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.35, random_state=seed)
- training データと test データ(35%)に分離(Kaggleのdataset使えばこういうの必要ない)
- from sklearn.tree import DecisionTreeClassifier
- tree_model = DecisionTreeClassifier()
- tree_model.fit(train_X, train_y)
- pred_X = tree_model.predict(test_X)
- 学習、予測
以上