Colab に Google Drive マウントして画像読み込ませるメモ
drive.mount('/content/drive')
%cd '/content/drive/My Drive/work'
と
import requests
import glob
from io import BytesIO
images = [
Image.open("./inputs/0.jpg"),
Image.open("./inputs/1.jpg"),
Image.open("./inputs/2.jpg"),
Image.open("./inputs/3.jpg"),
Image.open("./inputs/4.jpg"),
Image.open("./inputs/5.jpg"),
]
save_path = "./my_concept"
if not os.path.exists(save_path):
os.mkdir(save_path)
image_grid(images, 1, len(images))
でOK
気になったのでStelfieTTのプロセスを確認しておいた

この画像はあくまで自撮りのイメージでありstelfieTTさんとは全く関係ございません。
Stelfie The Time Traveller の画像作成プロセス概要を確認しておきました。
大まかな流れは以下のとおりのようです。
- Stelfie は 3d ソフトウェア環境にて作成された
- いくつかの画像はモデルを使い異なるポーズや異なる表情で撮影されました
- これらのスナップショットは Dreambooth のモデルとして使用されました
- モデルは良いリアルな結果となるように何度かファインチューンされました
- Stable Diffusion で制作プロセスを開始します
- Photoshop を用いて編集します
- 完全な結果が得られるまで SD と PS を繰り返します
おそらくそうかなとは思いましたがやはり Dreambooth を使ってモデルを学習し、Stable Diffusion で画像生成のようでした。
詳細のプロセスはこちら↓からご参照ください
簡単ですが以上になります。
transformers ライブラリを使用してBERTで文章生成させる際に起きたエラー修正記録
BERT のサンプルコードでエラーが出たので修正したログ
※作業履歴を記載した自分用メモです(散らかり注意)
- Tensorflow周りでエラー(libnvinfer.so.7 が無い)が出てそうなので記録
- エラーメッセージは↓
- tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory;
- Tensorflowのバージョン確認
- python -c 'import tensorflow as tf; print(tf.__version__)'
- 2.11.0
- CUDAのバージョン確認
- nvidia-smi
- 11.7
- CUDA11用にCUDNNをダウンロード
- インストール
sudo dpkg -i sudo dpkg -i ./cudnn-local-repo-ubuntu2004-8.7.0.84_1.0-1_amd64.deb- libnvinfer7のインストール
-
sudo apt-get install libnvinfer7=7.0.0-1+cuda10.2 libnvonnxparsers7=7.0.0-1+cuda10.2 libnvparsers7=7.0.0-1+cuda10.2 libnvinfer-plugin7=7.0.0-1+cuda10.2 libnvinfer-dev=7.0.0-1+cuda10.2 libnvonnxparsers-dev=7.0.0-1+cuda10.2 libnvparsers-dev=7.0.0-1+cuda10.2 libnvinfer-plugin-dev=7.0.0-1+cuda10.2 python3-libnvinfer=7.0.0-1+cuda10.2 ↑はうまくいかない- E: Unable to locate package libnvinfer7
- E: Unable to locate package libnvonnxparsers7
- E: Unable to locate package libnvparsers7
- E: Unable to locate package libnvinfer-plugin7
- E: Version '7.0.0-1+cuda10.2' for 'libnvinfer-dev' was not found
- E: Version '7.0.0-1+cuda10.2' for 'libnvonnxparsers-dev' was not found
- E: Version '7.0.0-1+cuda10.2' for 'libnvparsers-dev' was not found
- E: Version '7.0.0-1+cuda10.2' for 'libnvinfer-plugin-dev' was not found
- E: Version '7.0.0-1+cuda10.2' for 'python3-libnvinfer' was not found
- エラーメッセージは↓
-
-
とのこと。tensorflow upgrade- pip install --upgrade tensorflow
- 2.11.0で変わらず(すでに最新)
tensorrt を入れればlibnvinfer が入りそうなので試してみる- sudo apt install tensorrt
Unable to locate package tensorrt とのこと直接入れるかインストール方法-
ダウンロードページ -
とりあえずlibnvinfer7が無いとのエラーなので7系をダウンロード ダウンロードする際にいろいろとアンケートあり、開発するのに何がボトルネックなっとるか的な質問があった。管理大変すぎるにいれておいた。というかバージョンごとに動く動かないとか大変すぎる。7系だけでこれだけあるんだけど-

- んでバージョン毎に他ライブラリとの相性検討必要なら、環境構築だけで時間とられて開発開始できんやろと思います笑
-

- 7系にはCUDA11.7用のものは無し、と、あと自環境がubuntu 20.04 なのでこちらも無し。8系にしたほうがいいのかも。
-

- こちらにしよう。んで libnvinfer8が入るようなら 8 を必要とするtensorflow(があるのかわからないが)に切り替える作戦。あるいはlibnvinfer7にリンク貼る
- [1] sudo dpkg -i nv-tensorrt-local-repo-ubuntu2004-8.5.1-cuda-11.8_1.0-1_amd64.deb
- The public nv-tensorrt-local-repo-ubuntu2004-8.5.1-cuda-11.8 GPG key does not appear to be installed.To install the key, run this command:
sudo cp /var/nv-tensorrt-local-repo-ubuntu2004-8.5.1-cuda-11.8/nv-tensorrt-local-3E18D84E-keyring.gpg /usr/share/keyrings/といわれる - 言われたままに実行し、再度 [1] のコマンドを実行。うまくいったらしい。
- ls -al /home/tkoma2015/.local/lib/python3.8/site-packages/tensorrt/
total 898800
drwxr-xr-x 3 tkoma2015 tkoma2015 4096 Jan 5 23:31 .
drwx------ 353 tkoma2015 tkoma2015 20480 Jan 5 23:32 ..
-rw-r--r-- 1 tkoma2015 tkoma2015 5118 Jan 5 23:31 __init__.py
drwxr-xr-x 2 tkoma2015 tkoma2015 4096 Jan 5 23:31 __pycache__
-rw-r--r-- 1 tkoma2015 tkoma2015 487611688 Jan 5 23:31 libnvinfer.so.8
-rw-r--r-- 1 tkoma2015 tkoma2015 373749200 Jan 5 23:31 libnvinfer_builder_resource.so.8.5.2
-rw-r--r-- 1 tkoma2015 tkoma2015 48845176 Jan 5 23:31 libnvinfer_plugin.so.8
-rw-r--r-- 1 tkoma2015 tkoma2015 2860280 Jan 5 23:31 libnvonnxparser.so.8
-rw-r--r-- 1 tkoma2015 tkoma2015 3442680 Jan 5 23:31 libnvparsers.so.8
-rwxr-xr-x 1 tkoma2015 tkoma2015 3804080 Jan 5 23:31 tensorrt.so
- libnvinfer.so.8 なら入ったが、tensorflow が見に行こうとしていいるのはlibnvinfer.so.7 だ
- NVDIAのForumに似た状況の内容が記載されていた
- 参考になるかわからんが読んでみる
-

- Tensorflow 2.4.x から 2.5.x に upgradeしろと。すでに2.11.0いれてしまってるので、2.5.xにダウングレードすればうまくいくかも。動作確認取れているバージョンは以下の場所で確認できる模様
-
Forumで記載されていたようにTensorflowの2.5.xを使用してみる。 - pip install tensorflow-gpu==2.5.0
- でいいかな。問題なくインストール完了。
- バージョン確認
- python -c 'import tensorflow as tf; print(tf.__version__)'
- 2.5.0
- libnvinfer.so.7 がないとのエラーはなくなるOK
- NVDIAのForumに似た状況の内容が記載されていた
- 次は、 RuntimeError: Expected all tensors to be on the same device, but found at least two devices と言われる(エラー)
- import torch
torch.set_default_tensor_type('torch.cuda.FloatTensor') - とすれば良いらしい。実施し、エラーはなくなった
- import torch
- 次は、IndexError: Dimension out of range らしい
- が、ここからは元のソースを直せばいける気がするのでそれで対応
- 結果、無事BERTで文章生成に成功
- 動作確認できた簡単なサンプルコード( by chatGPT )
-
- 日本語でBERTやるなら、bert-base-japanese-whole-word-masking というのが良いらしいので、一応対応してみる。
- fugashi と ipadic は必要そうだったのでインストール
- pip install fugashi
- pip install ipadic
- 若干エラーでつつも動作はできた
- が、しかし良い感じに文章生成できるかというとそうでもなかった。
- モデルの選択や実際の実装依存でかなり変わってきそう
-

良い実装については別途調査してみる
Kaggle Tabular Playground - Aug 2022 実施記録
はじめに
Titanic チュートリアルに続き、Tabular Playground を選択(理由は必要リソースが少なそうだったから)して実施した結果です。
手法
LightGBM を使用、まずは実装が楽そうな LGBMClassifier を用いて学習(fit)、予測(predict)から結果を提出しました。結果は以下のとおり。

続いて、TrainAPIを用いて結果提出しました。結果は、

リーダーボードの上位は0.59444あたりなのでまだ随分差はありそうです。

ポイント
- 初回提出時のスコアが低かったのは学習方法を間違えていたため
- LightBGMのパラメタ周りをきちんと理解する必要ありそう
- Scikit-learn API の Classifier は Trainig API のラッパー的なものらしい(未確認)のでそれであれば Trainig API で細かくパラメタ設定できたほうがよいだろうと思い使用してみました。
- objective や metric、lambda_l1, lambda_l2、num_leaves, feature_fraction, bagging_fraction, bagging_freq, min_child_samples などのパラメタがあり(他にもあり)、それぞれについてきちんと理解しない限り適切は設定はできなさそうです。今回用いたパラメータは以下の通りですが、現時点ではざっくりとした理解のみです。
-
lgbm_params = {"boosting_type":"gbdt","objective":"binary","metric":'binary_logloss',"num_leaves":64,"max_depth":7,"verbose":0,}
- optuna によるパラメタチューニングもある程度有用そう
- num_boost_round=3000にして lightgbm で train した結果、スコアは0.52684 でした。条件変更せずに optuna を使用したところ、0.57918 となりましたので、チューニングをしていない状態からであれば効果は見込めそうです(今回は手動でチューニングしていないので、最終的に手動とどちらが優秀かは現時点ではわからない)
- before optuna=0.52684→after optune=0.57918
- 参考リンクtech.preferred.jp
- その他(細かな点)
- optuna 使用時(学習時)にノートPCがメモリ不足に陥り何度かページ表示が消えて、リロードで復活を繰り返した。おそらくもう少しメモリたりなければブラウザがおちるかPCが固まったと想像します(PCのメモリは 8GB)。Google Colab を使用したとて、結局ローカルマシンスペックがある程度必要ということかもしれない。この状態ではチューニングをきちんと実施したり、あるいは次のコンペに進むことはおそらく困難と思われる(メモリ増強はある程度必要)。
- (追記:2022/8/15)verbose_eval=False をオプション追加することでログの出力を制限したところ、メモリ不足は解消されました。メモリ不足解消されるのか試すためにもnum_boost_roundを3000→10000に増やして試行。メモリ不足とは別件ですが、スコアは3000のほうがよかった。

- (追記:2022/8/15)num_boost_round=10000が設定3000時よりもスコアが悪かったため、そもそもこの設定はoptuna使用時は不要なのかもしれません(仮説)。試しに本オプション無しで実行したところスコアは改善され、0.57860となりました(10000時は0.54程度)。なぜか0.579においつけない。

- (追記:2022/8/15)確認のため lightgbm + optuna ( num_boost_round=3000)を実施してみたところスコアは0.5618。昨日の値に届いていないため、微妙に設定が異なっていた可能性あり。少なくともoptuna まかせで回したほうが今日は良い成績がえられています。

- (追記:2022/8/15)試しに objective, metric 以外のパラメータを無しでoptuna を実行したところ、0.56532でした。どうやっても昨日の値に到達できそうにありません。

以上
Kaggle Titanicチュートリアルの次は?
ざっとコンペの内容を見てみたところ、おそらく以下2つはチュートリアルの次に実施するコンペとして良さそうです。コンペの概要説明にも新規向けというような説明がされていました。
- Tabular Playground Series

- Digit Recognizer

Dataサイズ比較
実際にコンペを実施するにあたりどの程度のデータサイズ(DLサイズ)のものを扱うことになるのか、他と比べてどうなのか見ておくべきかと思い確認しました(そもそも容量不足で扱えない等ありそうなので・・・)。
Tabular Playground Series が7.21MB、Digits Recognizer が128.13MB です(2022/8/13時点)。データサイズ的にはそれほどリソースが必要にならなさそうに見えます。Prize対象ではないようです。

ルールや制限
Taitanic チュートリアル実施時には制限などしっかり確認せずに進めたのでここでコンペのルールについて一度確認しておこうと思いました。全般的には以下のルールとなっているようです。もしWINNERになるようなことがあればそれなりにドキュメント整備や説明の機会を求められそうです。
共通ルール
- 1アカウント
- チーム外へのコード共有NG(フォーラム参加者に共有可の時はOK)
- チームマージはOK
- チームサイズ:5(コンペによって3など条件は異なる)
- submit制限(コンペによって3final submission や final submission制限がなかったりする)
- 5/day
- 2 final submission
- 実施期間
- コンペ毎に概要に記載されているが、無期限のものもある
COMPETITION-SPECIFICなルール、条件
- Prizeの条件など
- 勝者licenseについて
- Automated Machine Learning Tool (AMLT)を使う際の注意事項
COMPETITION RULE
PrizeやSwag, Knowledge のコンペには COMPETITION RULE が設けられている(Kudosのものには現時点ではCOMPETITION RULEの記載はなかったが、たまたまかもしれないので都度要確認)。Prize の場合は勝者には WINNERS OBLIGATIONS などがあり、ドキュメントの作成や説明を求められます。COMPETITION RULE は次の項目についての内容が記載されていました(一覧)。
- BINDING AGREEMENT.
- ELIGIBILITY.
- SPONSOR AND HOSTING PLATFORM.
- COMPETITION PERIOD.
- COMPETITION ENTRY.
- INDIVIDUALS AND TEAMS.
- COMPETITION DATA.
- SUBMISSION CODE REQUIREMENTS.
- DETERMINING WINNERS.
- Prize の場合:DERTEMINING WINNERS
- Swag、Knowledgeの場合:DETERMINING LEADERBOARD
- NOTIFICATION OF WINNERS & DISQUALIFICATION.
- WINNERS OBLIGATIONS.
- Prizeの場合のみ
- コードやモデルを提出
- 次のような内容のドキュメントや説明も求められる
- 手法について
- 重要な特徴量について
- 使用ツールについて
- 学習に必要な時間
- アンサンブルしたかどうか
- weightはどうしたか
- 最もワークした single classifier はあったか、それはどれか、single classifier のスコアは?
- 他competitor と何が違ったのか
- 詳細はこちらのブログに記載あり
www.kaggle.com
- PRIZES.
- Prizeの場合のみ
- TAXES.
- Prizeの場合のみ
- GENERAL CONDITIONS.
- PUBLICITY.
- PRIVACY.
- WARRANTY, INDEMNITY AND RELEASE.
- INTERNET.
- RIGHT TO CANCEL, MODIFY OR DISQUALIFY.
- NOT AN OFFER OF CONTRACT OF EMPLOYMENT.
- GOVERNING LAW.
以上
Kaggle のTitanicチュートリアルやってみたメモ
はじめに
Kaggleはどうなんだろうとふと思い立ちTitanicチュートリアルをやってみました。Submitまでの大きな流れは理解できたと考えます。初見のため他の方のブログを参考にし、たまたま openml のデータセットを用いる例を参照したことで、submit時にそれなりに迷いましたが、無事submitまでたどりつきました。迷って試行錯誤したことでより理解できたと良い方向に考えています。
Submit 記録↓
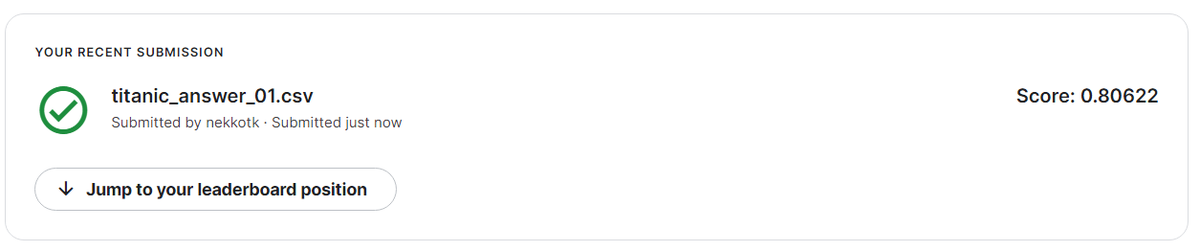
対象チュートリアル
実施環境
環境としてはGoogle Colab 環境で実施しました(Kaggle Jupyter Notebook、Google Colab どちらの環境がベターなのかわかりませんが、Google Colab は他でも使用していたため、今回も Google Colab を使用しました)。
Submit までの大きな流れ
- データセット取得
- データ前処理
- 学習、予測
- Submit
具体的な実施方法は多くのブログでも記載されている為、詳細はここでは記載しませんが素直に Kaggle が用意した学習データで学習し、テストデータを用いて予測、結果提出の流れがよさそうです。
はまった点(openmlのdatasetを使ったためにはまった点)
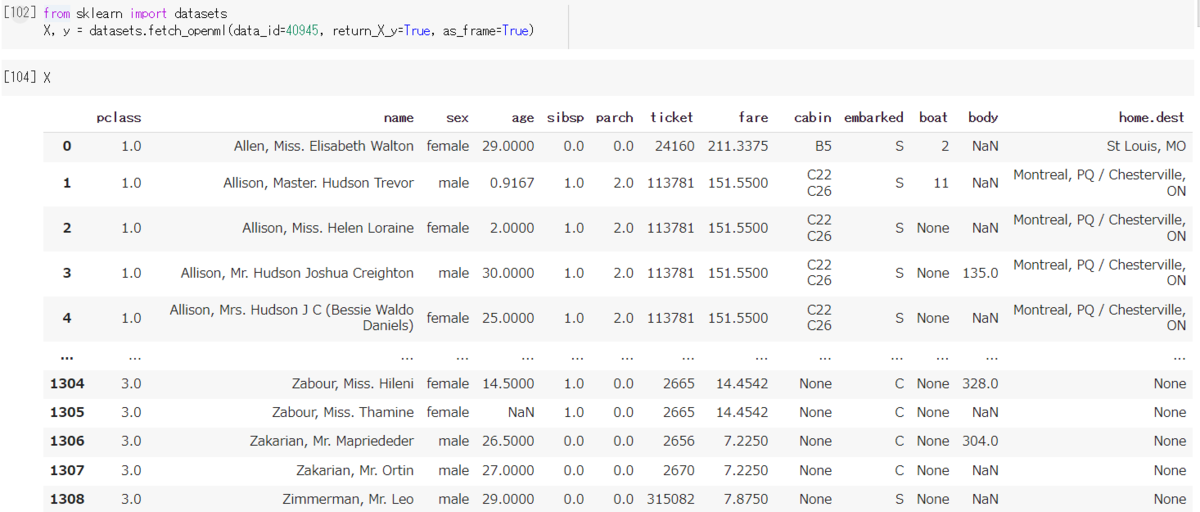
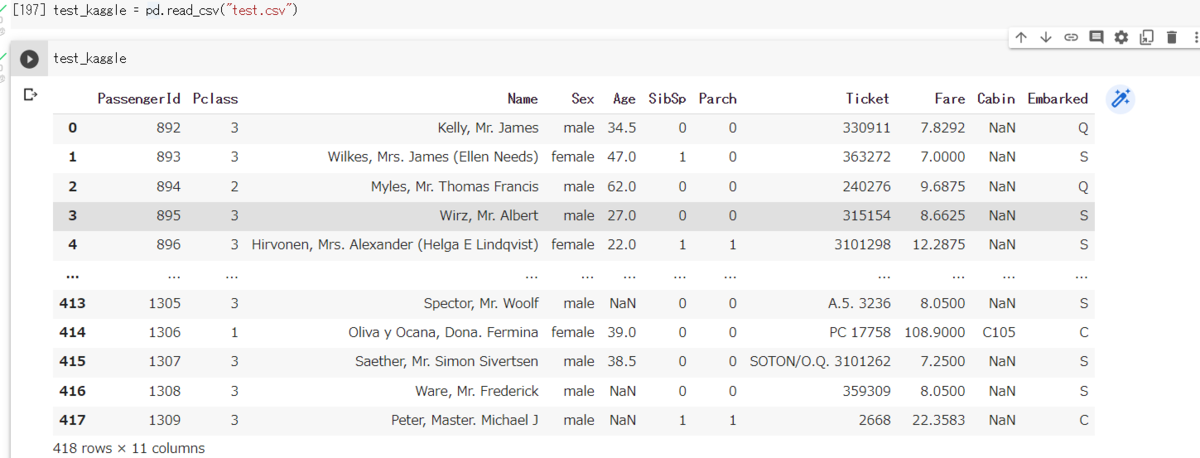
- Kaggleのdataset と列名が異なる
- Kaggleで submitするには列名を合わせる必要があるが、何を submit 必要なのかすら知らない初見では迷う。学習モデルを適用する際にも形式を合わさないといけない点も面倒。
- openml の dataset はこちら
- Kaggle の dataset はこちら
- test データと training データが分かれていない
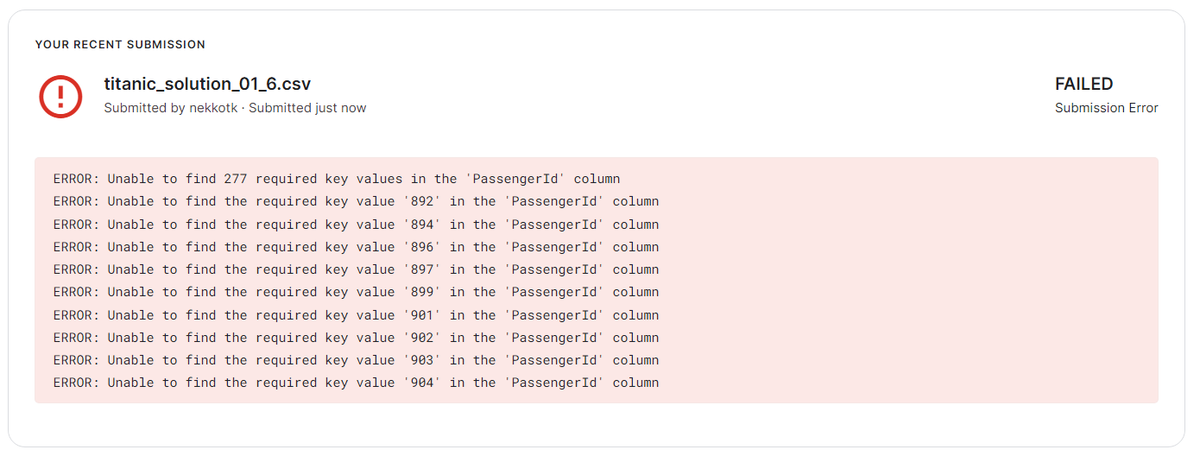
実施したコマンド達(メモ)
- X.isnull().sum()
- データ欠損チェック用(欠損数 0以外のデータで重要そうなものは対処必要)

- データ欠損チェック用(欠損数 0以外のデータで重要そうなものは対処必要)
- X["age"] = X["age"].fillna(X["age"].median())
- 中央値で補う
- X["embarked"] = X["embarked"].fillna("S")
- 多い数で補う
- X["sex"] = pd.get_dummies(X["sex"], drop_first=True)
- 文字列データを数値に置き換え
- 文字列データを数値に置き換え
-
X = pd.concat([X, pd.get_dummies(X["embarked"], prefix="embarked")], axis=1).drop(columns=["embarked"])
- 複数値を持つカラムを個別のカラムに分離
-
PassengerId = test_y.index.astype(int)
- int 指定
- my_solution = pd.DataFrame(pred_X, PassengerId, columns = ["Survived"])
- PassengerId と pred_X を組み合わせる
- my_solution.to_csv("titanic_solution_01.csv", index_label = ["PassengerId"])
- csvファイル出力
- feature_columns =["Name", "SibSp", "Parch", "Ticket", "Fare", "Cabin", "Sex", "Age", "Embarked","Pclass"]
- test_kaggle = test_kaggle.drop(columns=feature_columns, axis=1)
- 対象カラムをdrop
- from sklearn.metrics import accuracy_score
- accuracy_score(test_y, pred_X)
- 予測がどの程度あってるか確認
- from sklearn.model_selection import train_test_split
- seed=0
- train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.35, random_state=seed)
- training データと test データ(35%)に分離(Kaggleのdataset使えばこういうの必要ない)
- from sklearn.tree import DecisionTreeClassifier
- tree_model = DecisionTreeClassifier()
- tree_model.fit(train_X, train_y)
- pred_X = tree_model.predict(test_X)
- 学習、予測
以上
自動学習updateメモ
自動学習ツイートプログラムを改修したため記録
主な改修項目
- 文章生成時に連鎖しない場合はツイートしない
- 放置アカウント対策
- 感情分析
それぞれの詳細は以下のとおり
- 文章生成時に連鎖しない場合はツイートしない
- 経緯
- 学習元の文言そのままをツイートすることがあったため、それはあまりよくないだろうし、かつ何も生成していないので回避したかった
- 内容
- 文章生成時、次の言葉を決める際にどれだけ選択肢があるのかチェックをいれるようにした。選択肢が複数無いまま文章を最後まで生成してしまった場合はツイートしない対応とした
- 結果
- 新たに生成された文章のみツイートするようになった。例外としてたまたま元の文章と同じになることはある。あくまで結果であり、それに関しては許容している
- 経緯
- 放置アカウント対策
- 経緯
- 古い文章が残ったままの放置アカウントから学習してしまい。同じような文章を複数回生成するようなことがあったため対策必要と考えた
- 内容
- created_at をチェックすることで放置分については処理対象外とした
- 結果
- 放置対策がうまくいき、より直近の話題を学習できるようになった
- 経緯
- 感情分析
- 経緯
- たまたまネガティブな内容を生成&ツイートしてしまうことああった。ネガティブ度合にもよるがあまり好ましくないと感じた
- 内容
- 極性辞書ベースだと結構文言管理が大変だったりするので別のやり方がないか探していたところ、asari あるいは huggingface の bert-base-japanese-sentiment が良さげに見えた。どちらも試そうと試みたが、scikit-learn や numpy 他、いくつかのモジュールのエラー対応が必要だった。asariに関してはそれほど周辺のエラー除去が大変でなかったためこれを採用させて頂き、negative ツイートはしない方向とした
- 結果
- 現在稼働中でしばらく様子見、結果良好そうならそのまま稼働予定
- 経緯
その他環境的なメモ
- scikit-learn 0.22
- numpy 1.22.0
- asari 0.0.4
- joblib 1.1.0
- sklearn/feature/extraction/text.py でlen(original_tokens) の箇所がエラーのようだったので修正(list(original_token)したものをlenに入れる)
- AWS t2.micro では asari 起動時にKilledとなる。/var/log/syslog を確認したところOOM kill されているようだった。t2.small にインスタンスを変更(swapを設定する方法とどちらにするか迷ったが)
以上